
|
|
Forum Index : Microcontroller and PC projects : CMM2 - CSV Read
| Page 1 of 2 |
|||||
| Author | Message | ||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Happy Friday - only 8hrs till gin o'clock..... Not sure if this will end up being a super Noob question. �Here goes... If I have a CSV file with unknown columns and unknown rows what is the easiest / most efficient way to read the data into an array? �The file has a header row. �All the data is numeric. Imagine I just want to extract x,y data from x,y,z,a,b,c,d etc Currently I am: * Opening the file and reading the first row with Line Input * Then using Field$ to count the number of fields (stopping when field$="") * The reading all the data until EOF to count the number of records. * Close the file * Dim D(i,z) using the details just extracted for records and fields * Open file again * Read the first row to get the data headers * extract x and y headers --> assign to x$ and y$ * Read until EOF, adding data to D(i,z) as we go. All this works, but it bothers me that I need to read the entire datafile twice - once to extract the number of fields / dimension the array and then to actually read it. Back in my golden days of QBASIC - I would cheat by dimensioning an array bigger than I needed and then REDIM to trim the array down. What is / Is there a better way of reading CSV data into an array when you don't upfront know the number of fields or records? Context: I am using CMM2 to help teach graphing / analysing data and students have created a CSV with data in and we are now constructing the graphing portion. Cheers Nim Edited 2020-10-16 19:32 by Nimue Entropy is not what it used to be |
||||
| CaptainBoing Guru Joined: 07/09/2016 Location: United KingdomPosts: 2171 |
Assuming the header indicative of the number of columns and the rows are terminated with CRLF? (if you have quoted data it is more involved but we can deal later if you want) Open the file, read the first line and split on comma. The number of resultant fields is the column count for your array. call it CCt LINE INPUT all the way to the EOF - this is the number of lines, call it LCt then DIM CSV$(Lct,CCt) Close the file re-open it as #1 For n=1 to LCt Line Input#1,x$ <split x$ with whatever algo you want... FIELD? Not terribly familiar with CMM2 MMBasic For m=1 to CCt CSV$(n,m)=split field Next Next Close voila! your file is now in separate elements of your array does that help? |
||||
| CaptainBoing Guru Joined: 07/09/2016 Location: United KingdomPosts: 2171 |
forgot to say... if you have quotes in the data, you will need a bit more processing so you don't split on any , inside "" easily doable but a bit more involved. cross that bridge when you come to it. |
||||
| JohnS Guru Joined: 18/11/2011 Location: United KingdomPosts: 4335 |
(about CaptainBoing 1st post) I think that's what the OP posted :) John Edited 2020-10-16 20:48 by JohnS |
||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Thanks for the come back -- but I think that is what I'm doing (albeit in a clumsily explained manner) What I suppose I was asking in a longwinded way is: (1) Is there a CMM2 ish way of REDIM? >> I think no, other than building a new array and copying over. (2) Is it possible to get the number of records (rows?) without reading the entire file line by line << as this step then needs to be done twice -- once to get the size and once to load the array. As I'm never going to be creating datafiles with 1,000,000's of rows, I guess I'm asking for my development ;-) Cheers N Entropy is not what it used to be |
||||
| matherp Guru Joined: 11/12/2012 Location: United KingdomPosts: 11499 |
No, other than as you describe Only if they are fixed length. One tiny shortcut is to use SEEK(1) rather than closing and re-opening the file (I think - needs checking) |
||||
| mkopack73 Senior Member Joined: 03/07/2020 Location: United StatesPosts: 261 |
Why not store the record count in the header row? |
||||
| JohnS Guru Joined: 18/11/2011 Location: United KingdomPosts: 4335 |
CSV files don't, sadly. It's a REALLY crude (but very useful) file format. John |
||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Yes - we looked at ARFF files (as used in WEKA) - that have much more explicit headers. As this is for learning how to plot the data / create subs / functions, I might do exactly that and create a custom file format. eg: '.DAT file type Columns, 9 Records, 8 a,b,c,d,e,f,g,h,i a,b,c,d,e,f,g,h,i a,b,c,d,e,f,g,h,i a,b,c,d,e,f,g,h,i etc Ideally what I am wanting the students to create is a sub/function that lets them call plot_data(1,2,scatter,xlabel,ylabel,title) << where 1 and 2 are the columns that the data is in and the rest are the chart details.... Thanks for all the input - very much a work in progress.... Nim Entropy is not what it used to be |
||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Works a treat - even though the file was opened for INPUT not RANDOM. Nim Edited 2020-10-16 22:25 by Nimue Entropy is not what it used to be |
||||
| Paul_L Guru Joined: 03/03/2016 Location: United StatesPosts: 769 |
REDIM did not really re-dimension an existing array! It dimensioned a new array, copied the data from the old array into the new one, and then released the old array. This required that there be enough memory to hold both the old array and the new array in memory at the same time! It would crash if the combined arrays were too large. You could do this in MMBasic with a few lines of code, but it probably isn't worth it. Without knowing something about the csv file you will wind up with an enormously oversized array which would then have to be shrunk. 'Since you're dealing with a really fast SD card instead of a floppy disk just open the csv : count the fields : count the lines close the csv 'then dimension the array DIM a(lines, fields) 'then read the file open the csv for each line : read the line : parse the line : load the array close the csv Sometimes the direct way is the cleanest. Paul in NY Edited 2020-10-16 23:25 by Paul_L |
||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Interesting - never really considered what REDIM was doing behind the scenes. Will update when I get this finished. Cheers all N Entropy is not what it used to be |
||||
| thwill Guru Joined: 16/09/2019 Location: United KingdomPosts: 4369 |
MMBasic doesn't provide a mechanism to release a single variable does it ? ... so you can't emulate this in pure MMBasic ... and in any case you'd have to copy to and from a temporary if you wanted to end up with a larger array with the same name. Best wishes, Tom Edited 2020-10-16 23:45 by thwill MMBasic for Linux, Game*Mite, CMM2 Welcome Tape, Creaky old text adventures |
||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Again - never thought of this. If I dim(500,500) to calculate something -- is there a mechanism to then delete / release the memory if I no longer need the array? N Entropy is not what it used to be |
||||
| matherp Guru Joined: 11/12/2012 Location: United KingdomPosts: 11499 |
I wonder what the manual says  |
||||
| thwill Guru Joined: 16/09/2019 Location: United KingdomPosts: 4369 |
It says all manner of useful things but CLEAR is documented to delete all variables ... if there is a way to delete a single variable then it would be helpful if there was a reference to follow from CLEAR otherwise it seems not too stupid of me to assume that there isn't such a mechanism.Sorry, I haven't yet printed and read, and re-read the manual obsessively because the firmware author is an over-achiever and may yet require further additions to the manual  Best wishes, Tom Edited 2020-10-17 00:19 by thwill MMBasic for Linux, Game*Mite, CMM2 Welcome Tape, Creaky old text adventures |
||||
| Nimue Guru Joined: 06/08/2020 Location: United KingdomPosts: 427 |
Boom!! � I will learn one day. ;-) Edited 2020-10-17 00:26 by Nimue Entropy is not what it used to be |
||||
| matherp Guru Joined: 11/12/2012 Location: United KingdomPosts: 11499 |
MMbasic has always had a way of deleting a single variable, not specific to CMM2 - check ERASE in the manual |
||||
| thwill Guru Joined: 16/09/2019 Location: United KingdomPosts: 4369 |
I would, except at least in the copy I have, the list of commands in the manual jumps from END SUB to EXECUTE without having ERASE in between  May I feel vindicated, or would you care to cut me down with a withering comment ? Thanks Peter, that's awesome and may open up some further possibilities for mischief, Tom Edited 2020-10-17 01:00 by thwill MMBasic for Linux, Game*Mite, CMM2 Welcome Tape, Creaky old text adventures |
||||
| matherp Guru Joined: 11/12/2012 Location: United KingdomPosts: 11499 |
You are fully vindicated, both ERASE and ERROR seem to have gone missing in the V5.05.05 manual put are certainly in the 5.05.06 draft I've got from Geoff. 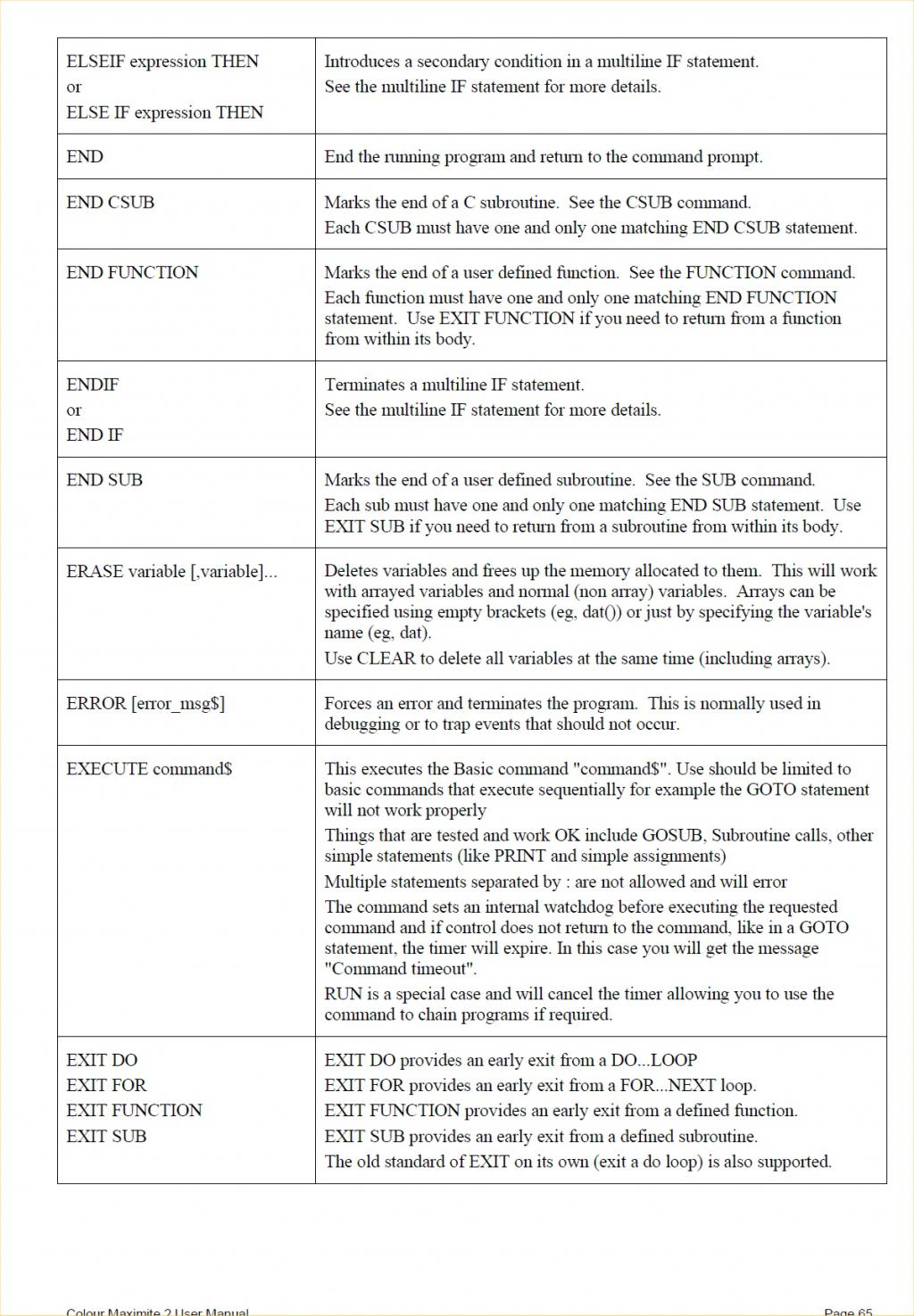 |
||||
| Page 1 of 2 |
|||||
| The Back Shed's forum code is written, and hosted, in Australia. | © JAQ Software 2026 |
